Honkit でつくられたドキュメント群を PDF で書き出すメモ
Honkit でつくられたドキュメント群を PDF で書き出すメモです。
Honkit で教材を作っていた
https://www.1ft-seabass.jp/memo/2021/11/15/summary-dhw-pp2-2021/
こちらの授業資料をHonkit で教材を作っていました。

こんなかんじです。
公式の PDF 化のナレッジはあるにはあるがうまくいかない
eBook and PDF · HonKit Documentation
こちらに公式の資料もあって PDF 化できそうなんですが、2021年11月現在 Windows だとバージョンの違いなのか PDF 化のコアとなる Calibre に対して連携できなくて、うまく PDF にすることができませんでした。
HonKitでMarkdown から PDFを作成する - Secret Ninja Blog
WSL で頑張れなくはなさそうなんですが、やっぱりバージョンが良くないなどエラーがめちゃくちゃ出るので、この路線は断念。
全ドキュメントを1ページにまとめて Honkit で書き出して PDF 印刷してしまおう
はい。できるだけシンプルに出来ないかなということで、こういう着地になりました。
- 全ドキュメントを目次ページである SUMMARY.md から結合する Markdown ファイル群を取得
- 全ドキュメントを1ページにまとめて Honkit で書き出し
- その1ページを PDF 印刷
でやってみます。
下準備
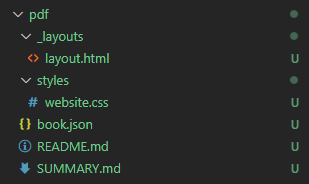
まず、今までのドキュメントは壊したくないので pdf というフォルダを作って、基本的な構造を移植します。
- layout.html
- website.css
- book.json
- SUMMARY.md
を持ってきます。README.md はひとまず空ファイルで。
SUMMARY.md
# Summary
- [README](README.md)SUMMARY.md は書き出し後の README.md だけなのでこのように記述しました。
元ネタの SUMMARY.md から全ドキュメントを 1 ページにまとめる Node.js のコード
こんな app.js を書きました。
const fs = require('fs').promises;
const path = require('path');
async function main (){
// SUMMARY.md から結合する Markdown ファイル群を取得
const filepath = path.resolve(__dirname , './base/SUMMARY.md');
const message = await fs.readFile(filepath, {encoding: 'utf-8'});
// Markdown のリンク記法の配列で入ってくる
let resultMarkdownLinkList = message.match(/\[(.*)\]\((.*)\)/gm);
console.log(resultMarkdownLinkList);
// 大量に取得してしまうと確認がしにくいので、いったん取得後に数件に限定する処理
// チューニング用
/*
resultMarkdownLinkList = [
resultMarkdownLinkList[0],
resultMarkdownLinkList[1],
resultMarkdownLinkList[2]
]
*/
// ファイルを結合して README.md 1ファイルに集約
let targetContent = "";
let targetContentAll = "";
for(let i = 0; i < resultMarkdownLinkList.length; i++){
const targetMatchResult = resultMarkdownLinkList[i];
// Markdown のリンク記法からリンクタイトルとファイルパスを抽出
const regexp = /\[(.*)\]\((.*)\)/gm;
const match = regexp.exec(targetMatchResult);
// console.log(match[1],match[2]);
const targetSummaryTitle = match[1];
const targetResolveFilepath = match[2];
// 相対パス化
const targetFilepath = path.resolve(__dirname , './base/' , targetResolveFilepath);
// 非同期でコンテンツ読み込み
targetContent = await fs.readFile(targetFilepath, {encoding: 'utf-8'});
console.log('----');
console.log(targetContent.substr(0,100));
// コンテンツ連結
targetContentAll += targetContent;
}
console.log('----');
console.log('コンテンツ書き込み');
console.log('----');
// pdf というフォルダに格納する
// この pdf フォルダを honkit で書き出し
const filepathMainContent = path.resolve(__dirname , './pdf/' , 'README.md');
// コンテンツ書き込み
await fs.writeFile(filepathMainContent,targetContentAll);
}
main();イレギュラーな状態をあまり想定していないですが、私の場合 base フォルダに全ドキュメントの Markdown があります。
その元ネタの SUMMARY.md から結合する Markdown ファイル群を Markdown のリンク記法で取得したあと、Markdown のリンク記法からリンクタイトルとファイルパスを抽出し、pdf/README.md にガシガシつなげました。
website.css の調整
印刷用の CSS として調整しました。
ページのサイズは A4 縦を上下左右 10 mmくらいマージンとったものです。body タグでは、それより少し小さく収まるサイズにしています。
.page-inner だけは、通常のレイアウトだと 60% が効いていて印刷時には変に狭く出てしまったので、このように調整しています。
/* 印刷用 */
@media print {
@page {
size: 190mm 277mm;
margin: 0;
}
body{
/*A4縦 210mm x 297mm*/
width: 186mm;
height: 270mm;
}
.page-inner {
width: 100% !important;
}
}book.json の調整
book.json も印刷レイアウト時に邪魔するプラグインを減らしました。
{
"title": "デジタルハリウッド大学院大学 2021 プロダクトプロトタイピングII 授業資料",
"description": "2021 授業資料",
"language": "ja",
"plugins": [
"anchors",
"hide-published-with",
"intopic-toc"
],
"styles": {
"website": "styles/website.css"
}
}こちらです。
"plugins": [
"anchors",
"hide-published-with",
"copy-code-button",
"intopic-toc",
"back-to-top-button"
]copy-code-button は印刷時には必要なかったのと、back-to-top-button は印刷後の全ページの右下にトップに戻るボタンが出てしまったので無くしました。
いざ書き出し
"scripts": {
"serve-pdf": "honkit serve pdf src-pdf",
"serve": "honkit serve base src",
"build": "honkit build base docs",package.json に serve-pdf という、今回の pdf フォルダの内容を src-pdf に HTML で書き出すコマンドを作って書き出しました。
npm run serve-pdf実行。

無事書き出されて http://localhost:4000/ で見ることができました。
PDF 印刷
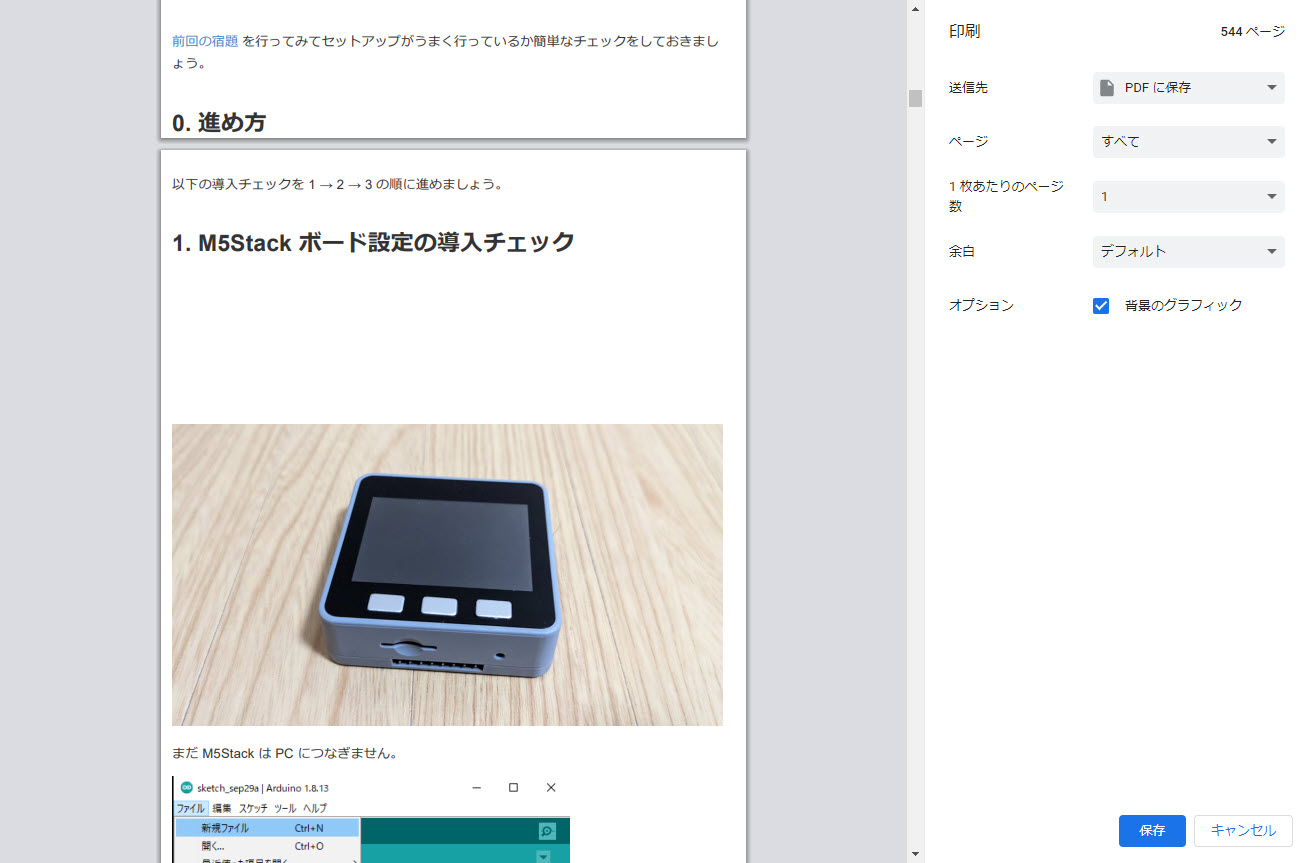
あとは Chrome ブラウザから PDF で印刷を選択しましょう。
今回は 500 ページ越えなので、取得に時間がかかりました!
無事出てきたので印刷します!
PDF 保存できました!
無事、生徒の希望にも応えれた
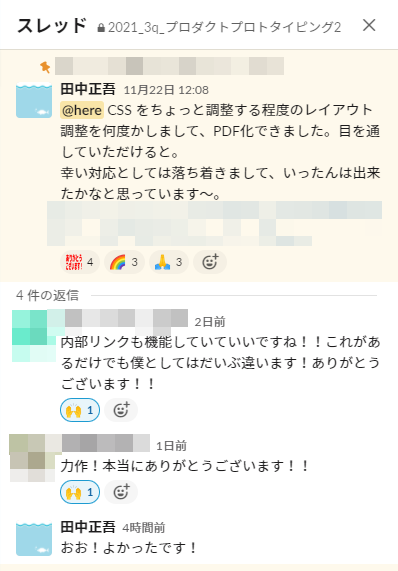
生徒の反応も上々な様子。
私も「どこかでまとめなきゃなー」と思っていた作業だったのがうまくいって良かったです。
今後、余裕があれば
- 改ページが読みづらい切られ方をするケースもあるのでできれば調整
- 印刷用 CSS をより良い感じに出来ないか模索
- Puppeteer やヘッドレス Chrome ブラウザで印刷自体を自動化
などなど、良くしていきたいなと思いました!